Note
Go to the end to download the full example code.
Go fast with multiprocessing¶
The streaming interfaces with iterables allow efficient batch processing as shown here. But still only one core/thread will be utilized. We will change that will multiprocessing.
Following example shows a batch feature extraction procedure using multiple CPU cores.
import multiprocessing
import os
import time
from itertools import cycle
from pathlib import Path
from typing import Iterable
import matplotlib.pyplot as plt
import vallenae as vae
HERE = Path(__file__).parent if "__file__" in locals() else Path.cwd()
TRADB = HERE / "steel_plate" / "sample_plain.tradb"
Prepare streaming reads¶
Our sample tradb only contains four data sets. That is not enough data for demonstrating batch processing. Therefore, we will simulate more data by looping over the data sets with following generator/iterable:
Define feature extraction function¶
A simple function from the module _feature_extraction is applied to all data sets and returns computed features.
The function is defined in another module to work with multiprocessing.Pool: https://bugs.python.org/issue25053
from __feature_extraction import feature_extraction # noqa
Compute with single thread/core¶
Note
The examples are executed on the CI / readthedocs server with limited resources. Therefore, the shown computation times and speedups are below the capability of modern machines.
Run computation in a single thread and get the time:
def time_elapsed_ms(t0):
return 1000.0 * (time.perf_counter() - t0)
if __name__ == "__main__": # guard needed for multiprocessing on Windows
time_start = time.perf_counter()
for tra in tra_generator():
results = feature_extraction(tra)
# do something with the results
time_single_thread = time_elapsed_ms(time_start)
print(f"Time single thread: {time_single_thread:.2f} ms")
Time single thread: 6464.97 ms
Compute with multiple processes/cores¶
First get number of available cores in your machine:
print(f"Available CPU cores: {os.cpu_count()}")
Available CPU cores: 2
But how can we utilize those cores? The common answer for most programming languages is multithreading. Threads run in the same process and heap, so data can be shared between them (with care). Sadly, Python uses a global interpreter lock (GIL) that locks heap memory, because Python objects are not thread-safe. Therefore, threads are blocking each other and no speedups are gained by using multiple threads.
The solution for Python is multiprocessing to work around the GIL. Every process has its own heap and GIL. Multiprocessing will introduce overhead for interprocess communication and data serialization/deserialization. To reduce the overhead, data is sent in bigger chunks.
Run computation on 4 cores with chunks of 128 data sets and get the time / speedup:
if __name__ == "__main__": # guard needed for multiprocessing on Windows
with multiprocessing.Pool(4) as pool:
time_start = time.perf_counter()
for _results in pool.imap(feature_extraction, tra_generator(), chunksize=128):
pass # do something with the results
time_multiprocessing = time_elapsed_ms(time_start)
print(f"Time multiprocessing: {time_multiprocessing:.2f} ms")
print(f"Speedup: {(time_single_thread / time_multiprocessing):.2f}")
Time multiprocessing: 4921.46 ms
Speedup: 1.31
Variation of the chunksize¶
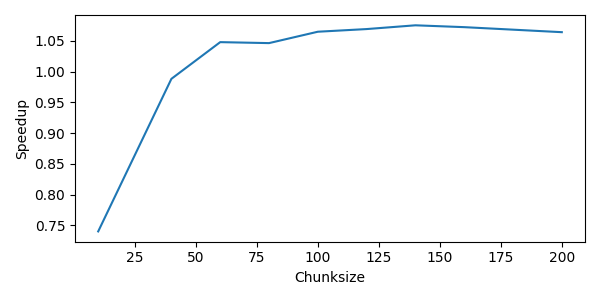
Following results show how the chunksize impacts the overall performance. The speedup is measured for different chunksizes and plotted against the chunksize:
if __name__ == "__main__": # guard needed for multiprocessing on Windows
chunksizes = (10, 40, 60, 80, 100, 120, 140, 160, 200)
speedup_chunksizes = []
with multiprocessing.Pool(4) as pool:
for chunksize in chunksizes:
time_start = time.perf_counter()
for _results in pool.imap(feature_extraction, tra_generator(), chunksize=chunksize):
pass # do something with the results
speedup_chunksizes.append(time_single_thread / time_elapsed_ms(time_start))
plt.figure(tight_layout=True, figsize=(6, 3))
plt.plot(chunksizes, speedup_chunksizes)
plt.xlabel("Chunksize")
plt.ylabel("Speedup")
plt.show()
Total running time of the script: (0 minutes 44.440 seconds)